
![]()
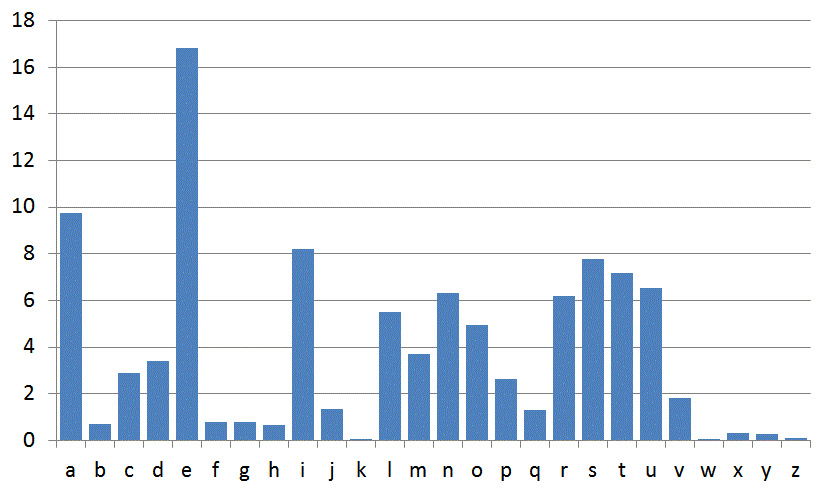
Il est interessant de connaitre l'histogramme d'apparition des lettre,
notamment la lettre "e" qui est facilement identifiable dans un texte
français (excepté dans La
disparition de Georges Perec )
Exemples d'histogramme (site http://www.nymphomath.ch)
:
 Analyse des fréquences en français |
 Analyse des fréquences en anglais |

| source=open(u'etranger04_sans_espace.txt',"r") txt="" i=0 texte=source.read() texte=texte.lower() print(len(texte)) car=(("a"), ("b"), ("c"), ("d"), ("e"), ("f"), ("g"), ("h"), ("i"), ("j"), ("k"), ("l"), ("m"), ("n"), ("o"), ("p"), ("q"), ("r"), ("s"), ("t"), ("u"), ("v"), ("w"), ("x"), ("y"), ("z")) l=len(car) print(l) nb=[0]*l max=0 somme=0 for i in range(l): nb[i]=texte.count(car[i]) somme+=nb[i] if max<nb[i]: max=nb[i] print("") for i in range(l): print(car[i]+" "+int(100*nb[i]/max)*"=") print("") for i in range(l): print(car[i]+" "+str(100.0*nb[i]/somme)[0:5]+" %") print("") source.close() |
|
 |